


無論選擇系統是排名還是檢索增強生成 (RAG),你的內容在未被索引之前都沒有意義。同樣的情況也適用於它出現的地方——傳統的 SERP、AI 生成的 SERP、Discover、Shopping、News、Gemini、ChatGPT,或任何未來出現的 AI 代理。
沒有索引就沒有可見性,沒有點擊,沒有影響。而且,索引問題不幸的是非常普遍。根據我與數百個企業級網站合作的經驗,平均有 9% 的有價值的深度內容頁面(產品、文章、列表等)未能被 Google 和 Bing 索引。
那麼,如何確保你的深度內容被索引呢?遵循這九個經過驗證的步驟,加速過程並最大化你網站的可見性。
步驟 1:審核你的內容以查找索引問題
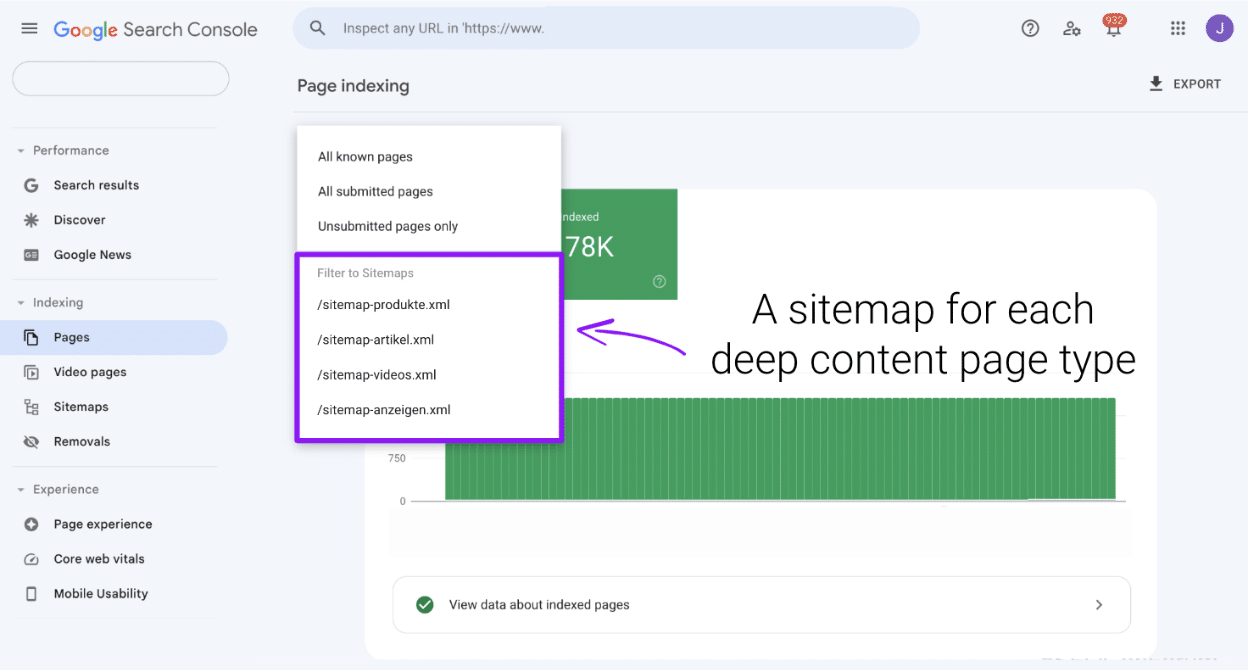
在 Google Search Console 和 Bing Webmaster Tools 中,為每種頁面類型提交一個單獨的網站地圖:
- 一個用於產品。
- 一個用於文章。
- 一個用於視頻。
- 等等。
提交網站地圖後,可能需要幾天時間才能在Pages界面中顯示。
使用此界面過濾和分析你的內容中有多少被排除在索引之外,更重要的是,具體的原因。

所有索引問題分為三個主要類別:
- 糟糕的 SEO 指令
- 這些問題源於技術錯誤,例如:
- 被 robots.txt 阻擋的頁面。
- 不正確的< a href=”https://searchengineland.com/canonicalization-seo-448161″>規範標籤。
- 無索引指令。
- 404 錯誤。
- 或301 重定向。
- 解決方案很簡單:將這些頁面從你的網站地圖中刪除。
- 這些問題源於技術錯誤,例如:
- 內容質量低
- 如果提交的頁面顯示軟 404 或內容質量問題,首先確保所有與 SEO 相關的內容都是在服務器端渲染的。
- 確認後,專注於提高內容的價值——增強頁面的深度、相關性和獨特性。
- 處理問題
- 這些問題更複雜,通常導致排除,如“Discovered – currently not indexed”或“Crawled – currently not indexed”。
雖然前兩個類別通常可以相對快速解決,但處理問題需要更多時間和關注。
通過使用網站地圖索引數據作為基準,你可以追蹤改善網站索引性能的進展。
深入了解:所有 SEO 需要知道的搜索四個階段
步驟 2:提交新聞網站地圖以加快文章索引

為了在 Google 中索引文章,請務必提交新聞網站地圖。此專用網站地圖包括特定標籤,旨在加速在過去 48 小時內發佈的文章的索引。重要的是,你的內容不需要傳統上“新聞性”才能受益於這種提交方法。
步驟 3:使用 Google Merchant Center 數據來改善產品索引
雖然這僅適用於 Google 和特定類別,但將你的產品提交到 Google Merchant Center 可以顯著改善索引。確保你的整個活躍產品目錄已添加並保持最新。
步驟 4:提交 RSS 源以加快爬行
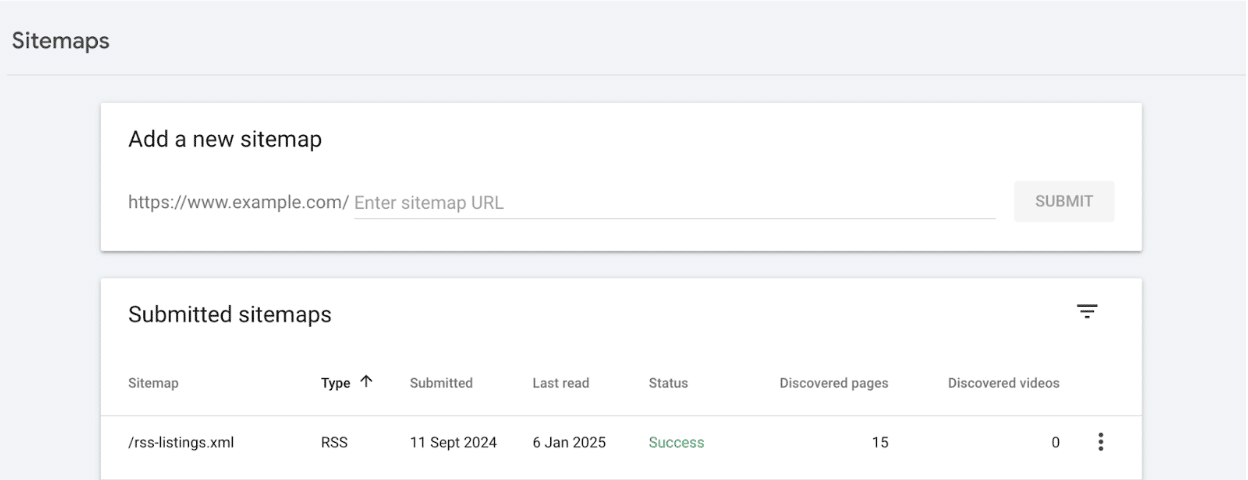
創建一個包含在過去 48 小時內發佈內容的 RSS 源。在 Google Search Console 和 Bing Webmaster Tools 的部分提交此源。這樣有效是因為 RSS 源本質上比傳統 XML 網站地圖更頻繁地被爬行。
此外,索引器仍然會對 RSS 源響應 WebSub 觸發——這是一個不再支持 XML 網站地圖的協議。為了最大化好處,確保你的開發團隊整合 WebSub。
步驟 5:利用索引 API 來加快發現
整合IndexNow(無限)和Google 索引 API(每天限 200 次 API 調用,除非你能獲得配額增加)。官方上,Google 索引 API 僅適用於具有工作職位或廣播事件標記的頁面。
步驟 6:加強內部鏈接以提升索引信號
大多數索引器發現內容的主要方式是通過鏈接。具有更強鏈接信號的 URL 在爬行隊列中優先級更高,並攜帶更多的索引能力。雖然外部鏈接很有價值,但內部鏈接對於擁有數千個深度內容頁面的網站來說,才是真正的改變者。你的相關內容區塊、分頁、麵包屑,尤其是首頁上顯示的鏈接,都是 Googlebot 和 Bingbot 的主要優化點。
在首頁上,你無法鏈接每個深度內容頁面——但你不需要這樣做。專注於那些尚未被索引的頁面。方法如下:
- 當新 URL 發佈時,檢查其對應的日誌文件。
- 一旦你看到 Googlebot 第一次爬行該 URL,立即觸發Google Search Console 檢查 API。
- 如果響應為“URL 對 Google 不明”,“已爬行,但未索引”或“已發現,但未索引”,則將該 URL 添加到專門的源中,填充首頁上的一個部分。
- 定期重新檢查該 URL。一旦被索引,從首頁源中刪除,以保持相關性並專注於其他未索引的內容。
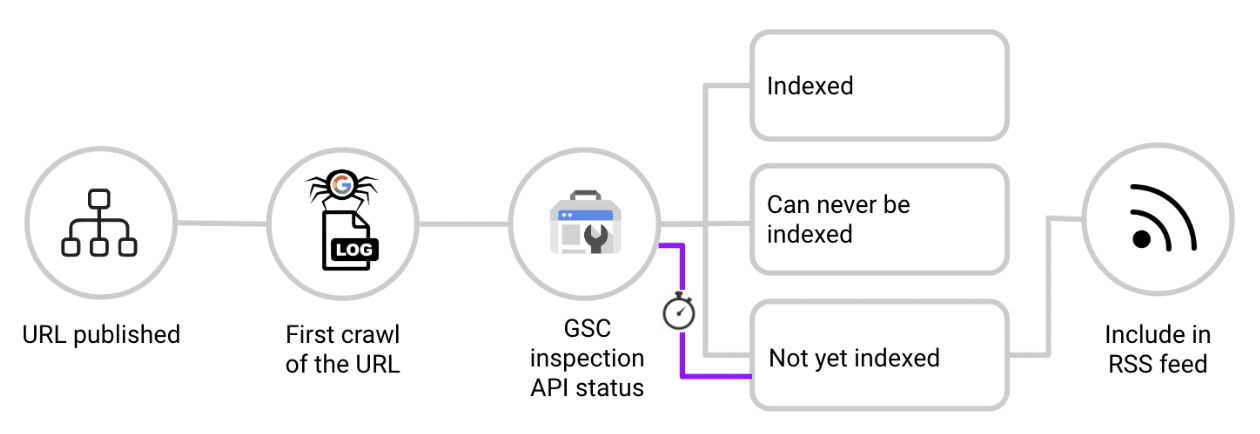
這有效地創建了一個實時的 RSS 源,鏈接來自首頁的非索引內容,利用其權威性來加速索引。
步驟 7:阻止非 SEO 相關的 URL 被爬行
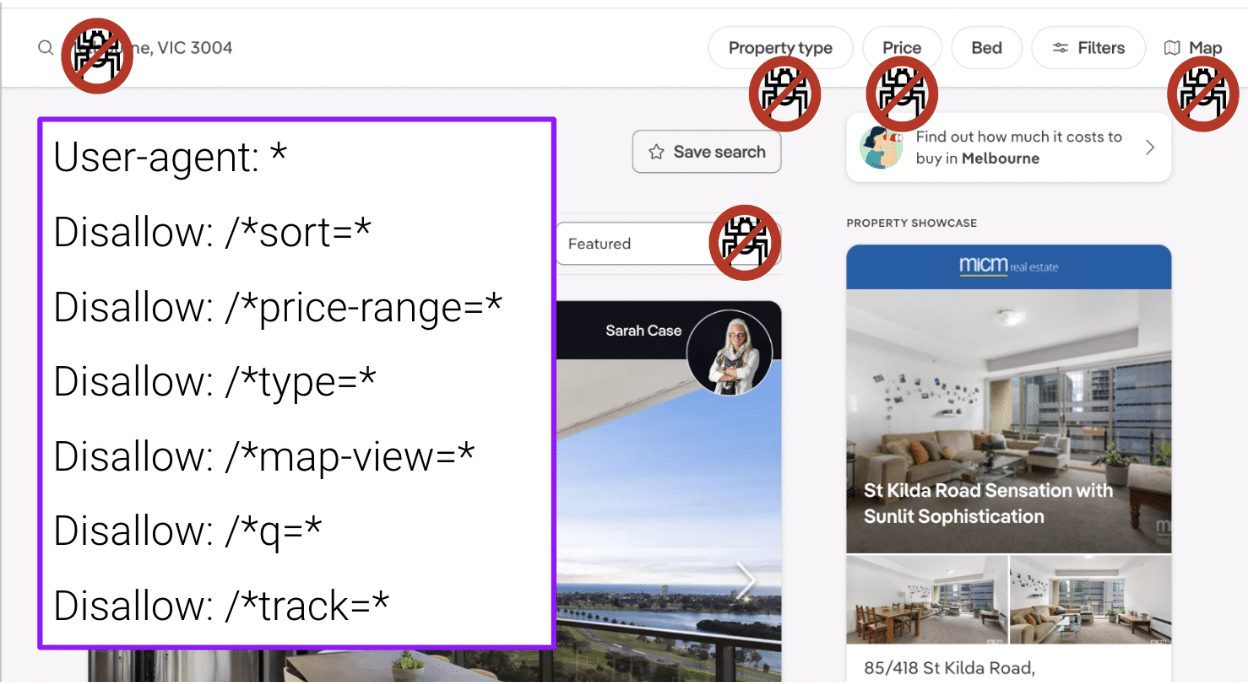
定期審核你的日誌文件,並使用 robots.txt 禁止高爬行、無價值的 URL 路徑。
如面向導航的頁面、搜索結果頁、跟蹤參數及其他不相關內容可以:
- 分散爬行器的注意力。
- 創建重複內容。
- 分裂排名信號。
- 最終降低索引器對你網站質量的看法。
然而,僅僅使用 robots.txt 禁止是不夠的。
如果這些頁面有內部鏈接、流量或其他排名信號,索引器仍然可能索引它們。
為了防止這種情況:
- 除了在 robots.txt 中禁止路徑外,對指向這些頁面的所有可能鏈接應用 rel=”nofollow”。
- 確保這不僅在網站上進行,還要在交易電子郵件和其他通信渠道中進行,以防止索引器發現該 URL。
步驟 8:使用 304 響應幫助爬行器優先考慮新內容
對於大多數網站,爬行大部分時間都用於刷新已索引的內容。

當網站返回 200 響應碼時,索引器會重新下載內容並與其現有快取進行比較。雖然這對於內容已更改時是有價值的,但對於大多數頁面來說並不必要。對於未更新的內容,返回 304 HTTP 響應碼(“未修改”)。這告訴爬行器該頁面未更改,允許索引器將資源分配給內容發現。
步驟 9:手動請求難以索引的頁面
對於那些仍然未被索引的頑固 URL,請在 Google Search Console 中手動提交。但請記住,每天限 10 次提交,因此請明智使用。根據我的測試,在 Bing Webmaster Tools 中的手動提交並不比通過 IndexNow API 提交有顯著優勢。因此,使用 API 更有效。
日本電話卡推介 / 台灣電話卡推介
更多儲值卡評測請即睇:SIM Card 大全
https://www.techritual.com/category/sim-card-review/
